Long story short: Yes! A flaky Internet connection to the outside world can make your local NFS client-server connections unusable. Even when they run on a dedicated storage network using dedicated switches and cables. This is a tale of dependencies, wrong assumptions, desperate restart of services, the butterfly effect and learning something new.
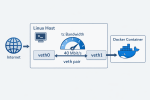
The company I work for operates 1000+ production servers in three data centers around the globe. This all started after a planned, trivial mass-restart of some internal services which are used by the online Control Panel. A couple of minutes after the restarts, the support team alarmed me that the Backup section of the Control Panel is not working. I acted as a typical System Administrator and just tried if the NFS backups are accessible from an SSH console. They were. So I concluded that most probably it wasn’t something with the NFS service but it was a problem caused by the restart of the internal services which keep the Control Panel running.
So we called a system developer to look into this. In the meantime I discovered by tests that the issue is limited only to one of our data centers. This raised an eyebrow but still with no further debug info and with everything working under the SSH console, I had to wait for input from the system development team. About an hour later they came up with a super simple reproducer:
perl -e 'use Path::Tiny; print path("/nfs/backup/somefile")->slurp;'
strace() shown that this hung on “flock(LOCK_SH)”. OMG! So it was a problem with the System Administrators’ systems after all. My previous test was to simply browse and read the files, and it didn’t occur to me to try file locking. I didn’t even know that this was used by the Control Panel. It turns out to be some (weird) default by Path::Tiny. A couple of minutes later I simplified the reproducer even more to just the following:
flock --shared /nfs/backup/somefile true
This also hung on “flock(LOCK_SH)”. Only in the USA data center. The backup servers were complaining about the following:
statd: server rpc.statd not responding, timed out
lockd: cannot monitor %server-XXX-of-ours%
The NFS clients were reporting:
lockd: server %backup-IP% not responding, still trying
xs_tcp_setup_socket: connect returned unhandled error -107
Right! So it’s the “rpc.statd” which just died! On both of our backup servers, simultaneously? Hmm… I raised the eyebrow even more. All servers had weeks of uptime, no changes at the time when the incident started, etc. Nothing suspicious caused by activity from any of our teams. Nevertheless, it doesn’t hurt to restart the NFS services. So I did it — restarted the backup NFS services (two times), the client NFS services for one of the production servers, unmounted and mounted the NFS directories. Nothing. Finally, I restarted the backup servers because there was a “[lockd]” kernel process hung in “D” state. After all it is possible that two backup servers with the same uptime get the same kernel bug at the same time…
The restart of the server machines fixed it! Pfew! Yet another unresolved mystery fixed by restart. Wait! Three minutes later the joy was gone because the Control Panel Backup section started to be sluggish again. The production machine where I was testing was intermittendly able to use the NFS locking.
2h30m elapsed already. Now it finally occurred to me that I need to pay closer attention to what the “rpc.statd” process was doing. To my surprise strace() shown that the process was waiting for 5+ seconds for some… DNS queries! It was trying to resolve “a.b.c.x.in-addr.arpa” and was timing out. The request was going to the local DNS cache server. The global DNS resolvers 8.8.8.8 and 1.1.1.1 were working properly and immediately returned “NXDOMAIN” for this DNS query. So I configured them on the backup servers and the NFS connections got much more stable. Still not perfect though.
The situation started to clear up. The NFS client was connecting to the NFS server. The server then tried to resolve the client’s private IP address to a hostname but was failing and this DNS failure was taking too many seconds. The reverse DNS zone for this private IPv4 network is served by the DNS servers “blackhole-1.iana.org” and “blackhole-2.iana.org”. Unfortunately, our upstream Internet provider was experiencing a problem and the connection to those DNS servers was failing with “Time to live exceeded” because of a network loop.
But why the NFS locking was still a bit sluggish after I fixed the NFS servers? It turned out that the “rpc.statd” of the NFS clients also does DNS resolve for the IP address of the NFS server.
30 minutes later I blacklisted the whole “x.in-addr.arpa” DNS zone for the private IPv4 network in all our local DNS resolvers and now they were replying with SERVFAIL immediately. The NFS locking started to work fast again and the Online Control panels were responding as expected.
Case closed. In three hours. Could have been done must faster – if I only knew NFS better, our NFS usage pattern and if I didn’t jump into the wrong assumptions. I’m still happy that I got to the root cause and have the confidence that the service is completely fixed for our customers.